Whisper
I am still alive and well! Ish. Things with kiddo have been busier than expected, and I got roped into some Helldivers 2 on many a night when I feel too tired to do a lot of intense coding. Still, I’ve been making some small progress.
So I may have found a new way to identify characters. On an unrelated project, i became acquainted with Whisper.cpp / Whisper-ai. Using this, it’s actually possible to just pull the voice clips from VOX.DAT and transcribe them. Even the higher model isn’t really that big (gig and a half for large-v3-turbo, which can do japanese). So after some testing in graphical, its actually quite accurate to transcribe the audio into Kanji, and from there determine what the missing characters are.
What I need to do is rewrite a new script that can walk through the XML for each voice clip and find any of the missing dictionary entries. Doing so will take some time, and in fact, it can be completely separate from the rest of the scripts. It just needs to identify all of the characters we’re missing.
Tooling this out will take a bit, but hopefully it can be automated to run through and finalize the characters once and for all. And it makes it much more accurate and easy, at least from what I’ve seen so far.
But it does give me further ideas. Since Whisper provides timestamps, I can match it to the subtitle durations in VOX.DAT as needed if I want to. Or have it generate them over again. But also it gives me a thought to include this into the GUI application as well.
The fly in the soup
Unfortunately I did find one problem. When we get into the hundreds of custom characters (over 255), the hex code changes from 0x96XX to 0x97XX, and finally 0x98XX. We don’t ever see a 0x9600 or 0x9700 so the number skips a little to be counted sequentially. I found a bug in my script that was adding 254 instead of 255 to the numbers. So my initial looks at the images were not aligning with the correct Kanji symbol, until I was working on a group of them and realized they were each off by one.
Here’s a listing of how they look, counted in one of the Nastasha calls. And the bug fix.
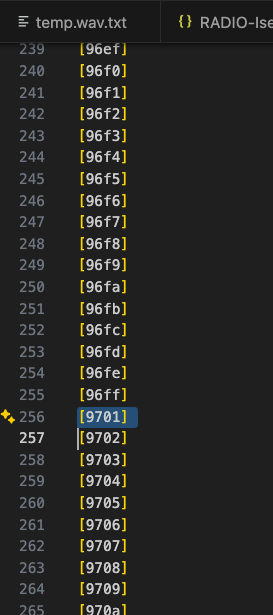
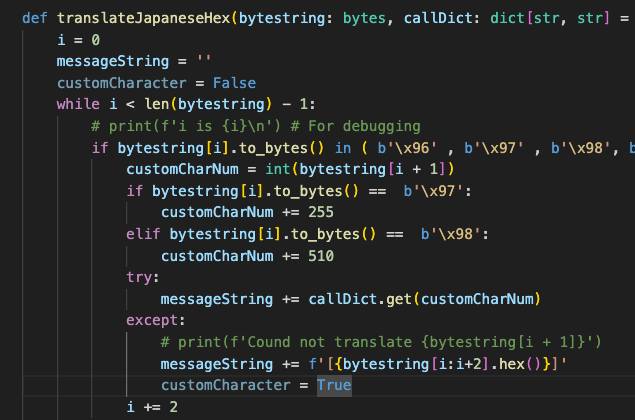
Unclear how many incorrect matches might already be here. We’ll have to just re-start from scratch. If you were making use of the script, I’m sorry, this might affect some of the pulled Kanji, depending on which call you pulled from. Does explain why i felt like some matches were incorrect in some of my automation (and manual) idents.
This doesn’t solve the problems with Staff calls either, but it might help narrow down some of what we’re having trouble figuring out.
Either way, I’m going back to the grind rather than griping about it too hard in a blog post. So here goes nothing.
-JRush