The Slowness of Translation
Translating sucks
In case anyone wonders why this takes so long, here’s a good example.
In thoroughness, or at least to go in order, I have a listing of what radio calls are found in GCL (Game command language) in each stage. GCL is how the developers programmed each stage with certain functions. Guard placement, routes, cameras, etc. Each actor can be added, and scripted to do what is needed. Within the GCL is also triggers for what codec call is initiated.
So one of the most massive undertakings is how to translate these calls, many of which are repeated. So I’ve broken them into two categories:
- Story calls
- Dialogue that can be replaced line by line.
The former is obvious, it’s a call that is called as part of the story. The second one is named this way as it’s a collection of individual lines for which there is a translation. This comes in handy because a lot of dialogue gets repeated. There are calls from Campbell or Meryl that say the same things depending on the state of the journey Snake is on. Nastasha for example gives weapon tips, and Mei Ling has her proverbs. These things can be listed in multiple calls called by different stages.
My workflow
So my workflow goes like this. For each stage I have a listing of the calls that are in that stage. Here’s the dock stage (csv):
offset,call hex,frequency,call data offset
5990,0137050a,14085,01045460,283744
14233,0137050a,14085,0b0ef61e,980510
14397,0137050a,14085,000ee180,975232
14543,0137050a,14085,000ee180,975232
14610,0137050a,14085,000ee180,975232
14718,0137050a,14085,010ee494,976020
14758,0137050a,14085,010eee37,978487
14798,0137050a,14085,000ef132,979250
14867,0137050a,14085,000ef132,979250
14932,0137050a,14085,000ef44f,980047
From left to right we have
- Offset of the call in stage.dir (these were from extracted gcx files)
- Call hex is the hex of the frequency (seen in the next one) with the preceeding and following byte. This was to make sure what i was pullign were actual calls in the gcl.*
- The frequency of the call.
- The call data offset from Radio.dat (The 2nd to last is hex, the last is the int value)
* – In my workflow for finding this, I found it would more or less be aligned to have 0x01 before nad 0x0a after. This way if I hit somewhere else that used 0x3705 for something other than the colonel call, i would know to discard it from my list. Thats how reverse engineering works! Make sure it fits a pattern before you move forward…
So first I did the Dock stage, s00a, which had those calls listed above. Mostly were instructions like how to crawl, various weapon actions, etc. Again, since they were repeated I figured we could do a find and replace as it’s not too intensive to load this as a dictionary and just do a replace all for each one.
Then, I move onto stage s01a (Heliport and more) and there’s a list of…. oh, 37 calls. :|
So as I start making my way through them, eventually we hit some of the longer calls from Nastasha, which have quite the extended run length. Call offset 1393925 is nearly 130 lines of dialogue. Some repeated, some not. So here’s a screenshot of me going through them.
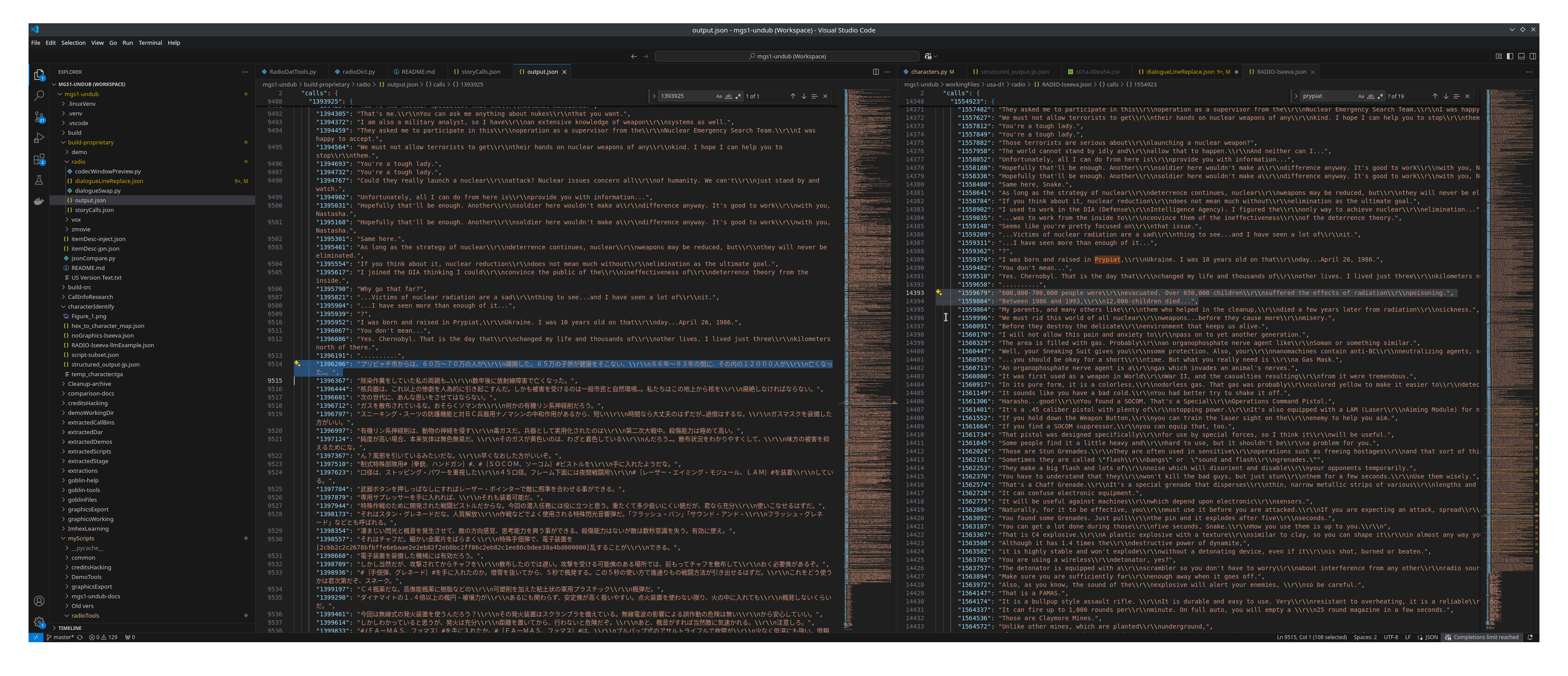
On the left is the Japanese script, and on the right is the US version. So the workflow is like this:
- Pop the line into google translate to see what it says
- See if the line in the US version matches.
- If so, replace. But if not…
- Check to see how different it is. In this case it looks like there’s so much content it was split over two lines.
- Also to consider, are there any unidentified characters in the line of dialogue?**
** Regarding this, in the last post I discussed how character identification for images stored in the RADIO.DAT file is a problem. How my script outputs anything not identified is in square braces [] with the 36-byte hex in as a string. This way I could find these easily when going through to identify them.
Currently the line I’m looking at is:
Japanese:
プリピャチ市からは、60万〜70万の人が疎開した。65万の子併が健康をそこない、86年〜93年の間に、その内の12000人が亡くなった…。
English:
"600,000-700,000 people were\\r\\nevacuated. Over 650,000 children\\r\\nsuffered the effects of radiation\\r\\npoisoning."
"Between 1986 and 1993,\\r\\n12,000 children died..."
Notice that the dialogue for the first line in english is super long, and it doesn’t cover everything. Codec dialogue is essentially limited to 4 lines, so if you see more than 3 line breaks (\r\n as written) then it’s not gonna work…
So here’s where it becomes a bit more difficult. Do I back up and see if two lines can be inserted? Or do I try to cram it all into a more succint single-line?
Up till now I’ve been mostly doing the latter. You can trim out words. Like Kevin and his small words. But, is something lost? I guess you be the judge.
This is something where I think it would be helpful to manually edit and figure out if we can inject a second line of dialogue in VOX.DAT. You can do so in gameplay. But I haven’t tried in Radio as timings aren’t stored here, and if we add another, how will the game know how long that line is suppsoed to be?
Here’s a weird quirk. RADIO.DAT has the dialogue for the actual on-screen subtitles. But all that dialogue is mirrored in VOX.DAT. And any 0xff02 commands in RADIO.DAT point to VOX.dat for the voice lines. It contains the audio, the lip sync animation, and liek Demo, which frame the text is shown, and for how long, and the text. But the text doesn’t matter, since we pull from Radio.
The bigger problem I see here is those changes would have to stay in sync…. so…. editing these would come with a mandatory change to both sides. Haven’t even tested this yet, but I was inspired by a friend of mine who is working on developing a game in Godot. He’s also created a very slick looking Pomodoro timer app. I wondered if that might be a way to start looking at a front end for this.
What that means for later… some ideas.
I’m mostly for open source software. And of course the source for all of my scripts are available. But if I were to take the time to develop a front end, that might end up being a paid feature. I think it’s better to keep to the command line, but I know there will be others who maybe want to make their own translation, from this or other languages. We’ll see what happens there. It’s a dream, but I might get there one day.
Anyway, this gives me two directions to go.
- First, todo, I need to adjust the RADIO.DAT recompiler with a new feature, which is to flag which calls are edited, and which are not. This way I could continue making story call additions, and then have some calls re-compile with their original binary text data. My translator is pretty good about putting text back together, but the graphics data is an issue when something is not matched.
I did consider doing more to handle re-injecting those repeated custom characters that weren’t identified, but I figured it made the script more complicated than necessary for now. For integrity testing, there’s an option in the script which uses the original hex (not translated) to ensure the re-compiler was working properly. If this could be used on command, it could inject calls I’ve changed and leave the rest intact.
This is kind of on my list already as it works around some calls that don’t recompile correctly, messing up offsets.
- Making a more robust tool that allows for multiple dialogue injections would be good. I can already inject new dialogue lines (extra subtitles for long japanese text) in Demo, Zmovie, etc. Those are stored with a start frame, and duration. You can just shorten the duration and add another line that starts at a later frame, so long as it doesn’t collide with the next.
Why localization is a concern
Anyway, I hope this is more insight into why it just takes so fricking long to translate. And why localization starts to become a thing. It forces me to think critically about balancing the original dialogue, the new dialogue, and how we can say things differently for space constraints.
And honestly, sometimes why I look at the original so fondly is that there’s a completely different rhythm to their voice acting. You can really tell there’s more play off each others’ acting chops.
Further, as I would’ve mentioned earlier, but there’s just so much to this project I mention it where I can… there’s a lot of subtitles where things are out of order. Here are a few things that bugged me enough to change…
CAMPBELL:
"The nuclear weapons disposal facility on Shadow Moses Island"
"in Alaska's Fox Archipelago"
"was attacked and captured by Next-Generation Special Forces"
"being led by members of FOX-HOUND."
The intro bugged me because of the placement of text in the original Japanese. You can clearly make out when Campbell says “Alaska” or “Shadow Moses” or “FOX-HOUND” and they are not at all where the english subtitles are. So I adjusted it to be this:
CAMPBELL:
"In Alaska's Fox Archipelago,|on Shadow Moses Island..."
"FOX-HOUND, along with the|Next-Generation Special Forces..."
"...led a revolt and successfully|took control of the"
"Nuclear Weapons Disposal Facility|located there."
And another point, later on, the order in which the FOX-HOUND members names and roles are stated…
Japanese:
"An interrogation specialist and formidable gunfighter..."
"Revolver Ocelot."
English:
"And Revolver Ocelot,"
"specialist in interrogation and a formidable gunfighter."
It’s not that I want to mess with the dialogue. It just doesn’t really fit well. So these are minor changes I’m taking liberty to do where I can to ensure someone watching understands the flow.
There are also plenty of funny things I see along the way from google translate. I think I mentioned this before, but Meryl’s “Women have more hiding places than men” translated as having more “Drawers” which, is probably the same intent, but a lot more awkward to say. Based on the punctuation, I think she’s a bit embarrased about how it came off, and moves on quickly.
There’s also a lot of times someone says “Listen…” separately from the dialogue as is in the USA version, or when Snake’s name is moved around from the start to the end of a line. Liquid’s lines in the Dock cutscene are completely reversed, so I moved lines to match and just made it a little more in line with the orignal translation:
"Listen, I know he'll be|coming through here."
"Don't let your guard down."
"I'm going to swat down|a couple of bothersome flies."
The workflow… final thoughts, and a project update
I had been thinking the past few days about my use of AI last time. I think the reason I keep rebelling against using AI completely for some tasks is I don’t trust it. I don’t want code running here that I don’t fully understand. It’s helpful in some places mostly where I can build something to quickly extract things, or find patterns. But not for the actual translation.
I am considering coming back to it to review more of the codec dialogue that has special characters in it. I think it might be better to get a good model that looks for differences in the text, but it may involve some new tooling I’m not ready to commit time to.
But here’s why there are a few things that probably sound bad to the casual observer of the project:
- Do I use google translate?
Yes. It’s necessary to understand what is being said in each line to match against the english. I’m not trying to use the robotic basic translation, but it helps identify what I need to put in.
- Are you putting in the USA dialogue?
Where I can. Examples above demonstrate how I’m adjusting things.
- Why not do a full translation?
I don’t know Japanese well enough to do justice. If you want to do a full localization, be my guest, but thats what the tools are for. I’d love to have some folks on my team that can do this, but as it stands this is a personal project. I also fear the risk of having to overrule a decision someone disagrees with me on.
In the end this has become a project that is a lot more personal to me than I anticipated. I don’t know that I’d hand the translation pen to just anyone. But nor do I think I’m close to finishing alone.
–
Anyway, the update is I’m taking a bit of a break from the project. I think my exhuberance for AI was a bit away from my core values, which is that AI is to be used to assist, but not to write my code (with those few exceptions). I don’t think the LLM was the best idea so far to translate, and in fact I had more success when I switched to a non-AI algorythm for finding the cooresponding dialogue.
I think if I move forward on translation, it will be more story focused. That allows me to get to my core goal of letting someone play this game with english subtitles. Covering the story is the best first attempt. I can worry about optional dialogue later. Hell I’ve even translated a couple Telops and the item descriptions. So, the “first draft” release, if i choose to release it, will have quite a lot going for it.
So anyway, there’s a lot going on in my personal life, and this is a passion project, so I’m not stepping away. But I’m slowing down so I don’t get overzealous and make some shortcuts with AI or code too simple for the task that I regret later. I’ve got some planned modifications to the Radio recompiler, as mentioned, and those will need some careful tweaks, probably in a testing branch, before i can say they’re ready.
And there’s always some old code I rushed through as is that could be more robust.
More to follow, but I hope this shows the scope and depth of the project, and why there’s really no good timeline I can give right now on its conclusion. I do want it done sooner, rather than later, since Sons of Liberty is my favorite game of the series, and of course I can’t wait to get to what comes next ;) But for now, this is what we’ve got.
Anyone interested in helping with the project, please reach out to me on Discord. I did create a gitlab where the dialogue files can be uploaded away from a public github, and am happy to use that as a basis for collaboration.
Otherwise, let me know what you think!
PS. I’m not poor but feel free to buy me a Ko-Fi.
I added a Ko-Fi Page for anyone who wants to throw me a couple bucks. I have a day job, and it’s not like it affects the pay I get for the project (which is none) but if you like what I’m doing and want to send a tip, feel free :)