Master Collection Solves the Character issues!
Blog post:
Alright folks. Time to work on the project has been a bit dicey, but I actually have some fantastic news that is all thanks to some recent developments from Konami.
I’m sure if you are a Metal Gear Solid fan you’re aware that the Master Collection Vol 2 was just announced. What you may not have seen is that vol 1 also received a major graphical overhaul.
Their preview video is here, note that subtitles are now in high definition characters.
As I haven’t yet dived into modding the master collection yet I took this as a time to investigate as it was possible that if they had pancakes the text, the full text might be accessible. This would be the solution to all of the missing Kanji if the dialogue was all properly set.
So it started with cracking open the data, and finding the Integral dish patches. I had some great help from Nuggs and some of the other folks working on the M2Fix patch. They directed me to a specific file that contained literally all of the dialogue in the game!
After some investigation I figured out the patterns.
First there is a table of contents that matches the offset of the dialogue in the patch with the offset of the demo, vox, or other file they correspond to (based on their original 0x800 block offset
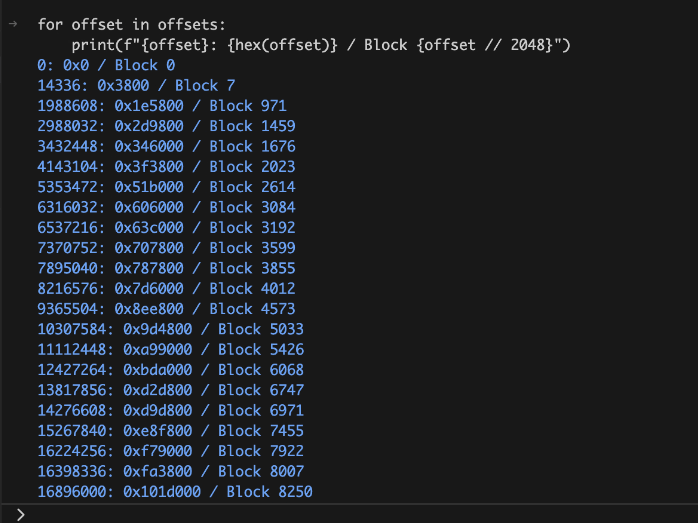
Took me a couple queries to figure out they were instead encoded in EUC-jp, which was new to me. Then, the dialogue is slightly different in terms of line breaks. For a demo or voice clip, every new line is the same “|” character for a break, and then an actual \n for a new like for each subtitle change.
It makes it super easy to pull a json, so my plan was going to be to make a flow like this:
- Extract all dialogue from the patch
- Compare to the extract of the game
- Correct any mismatched Kanji characters
- Output the new dicts to be replaced in the Characters.py file for translation
It would take some coding but super possible and not hard. Only there was small problem.
After running it on the integral patch I was missing the staff calls. Which account for a ton of the missing characters, and as of yet aren’t fully listed somewhere.
I had recently started using Claude code and as a research exercise I had it liking fit anywhere on the internet with the staff dialogue transcribed out. I came across a couple partials but nothing in full. One notable was an article on a fan site which has an awesome article discussing the staff commentary.
Here’s a link to the article: http://www.hardcoregaming101.net/metal-gear-solid-integral-staff-commentary/
I reached out to the editor asking if they by chance had them handy still, and the article writer was kind enough to respond. But unfortunately we were still in the same boat. He had transcribed via OCR and hand with context. Same as I had been doing. Slow progress. And since there are randomization triggers, it’s hard to trigger all of the dialogue from in game.
Huh. Well, that was frustrating. I tested the game in high graphics mode and indeed the staff calls do appear in high resolution Kanji.
Several thoughts occurred to me looking into this. First off, the initial demo from Konami’s trailer looked like it was upscale, which didn’t seem possible with how degraded the kanjis are in game.
The second was a concern that nagged at me was that based on what I read in the file I extracted. It didn’t look like radio dialogue was pulled (at least in the radio order). It looked like it was pulling from vox. That’s good from a standpoint of having it. Where is doesn’t make sense is that the game has the dialogue there but it is unused. Only timings are pulled from vox. The text itself is still read from radio.
This had me convinced that the radio dialogue must be somewhere. But after searching binary patterns across literally every file I was still coming up empty.
Then it hit me. Let’s search by one of the 36-byte graphic data strings.
Bingo. Found a file called frontall.bin. One look at the offset showed me clearly that yes, this is another group of graphics.
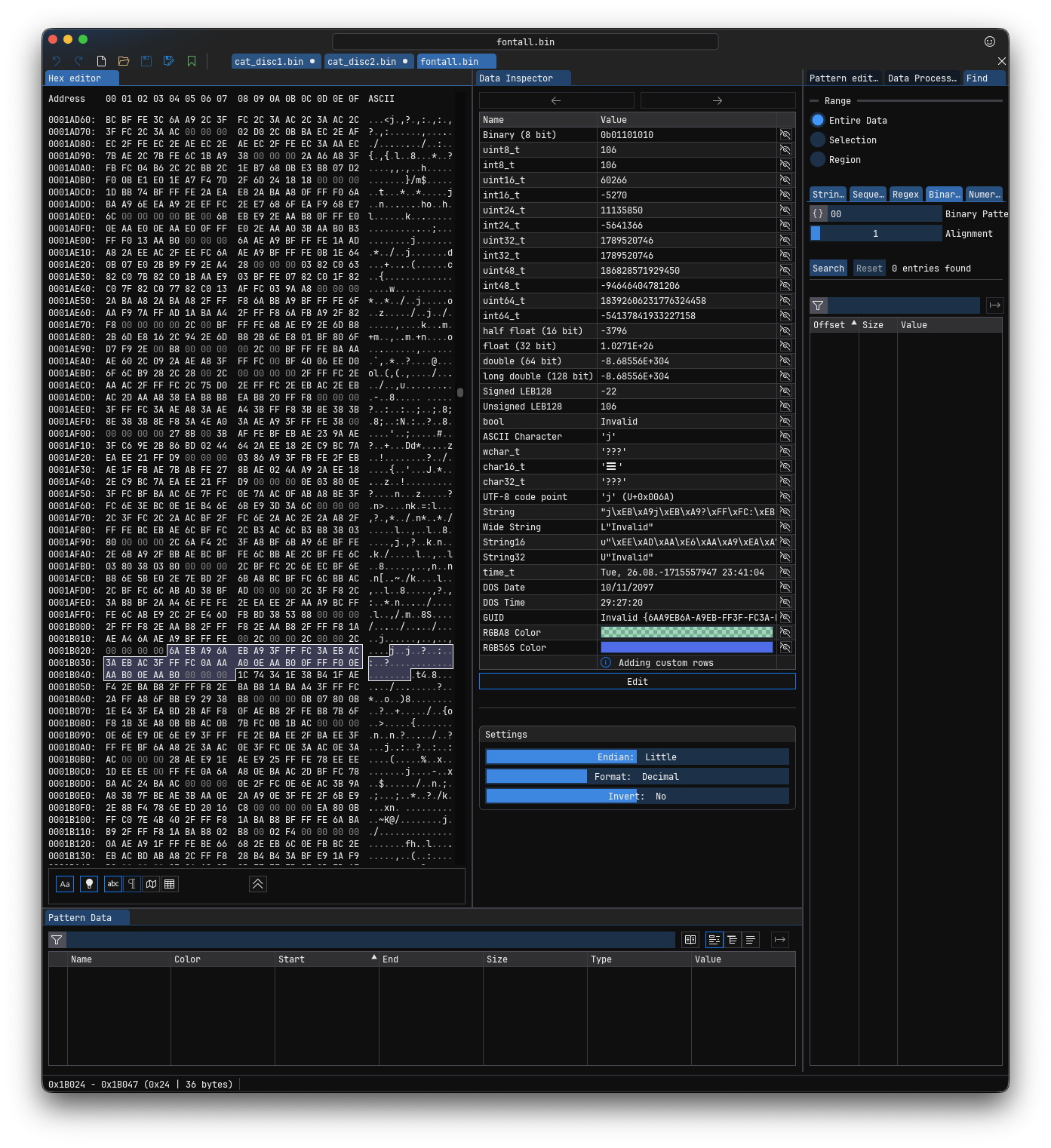 In the above screenshot, it’s clear to me that this is graphic data, because when I was typically seeing it in game data, we always have this cascade of three null bytes through the file. You can select 36 of them as I have to see how the pattern is ongoing.
In the above screenshot, it’s clear to me that this is graphic data, because when I was typically seeing it in game data, we always have this cascade of three null bytes through the file. You can select 36 of them as I have to see how the pattern is ongoing.
This might be even better though, because if there is a giant list of graphics, there must be a lookup table, I thought. And there must be like a character vs. offset table somewhere.
But looking earlier in the file there was no pattern. So I asked Claude with the example of the graphic and his response blew me away.
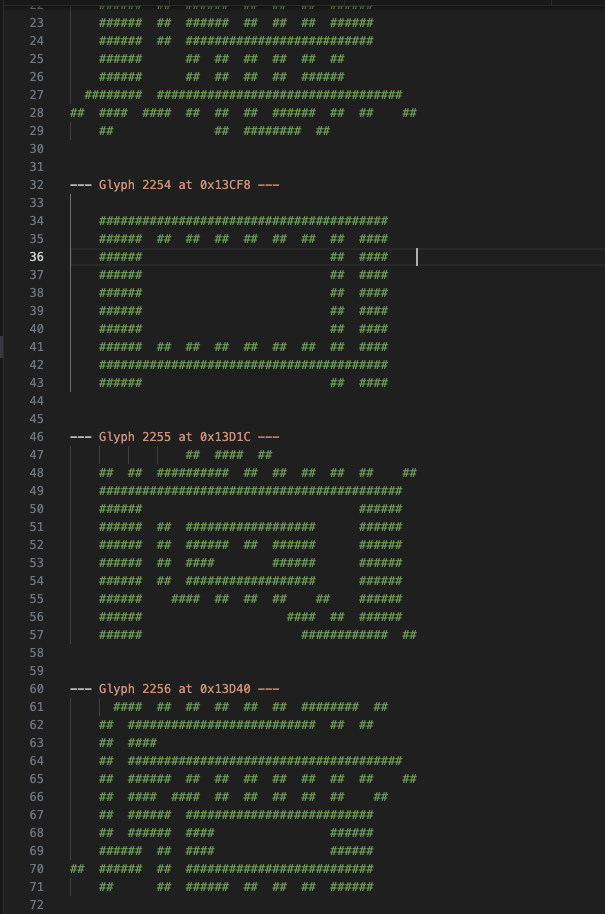
Despite my insistence that hiragana and katakana are likely not there, Claude determines the entire file is 36-byte characters, and they align in order to JIS 0208 standard Unicode. Claude even figured out itself how to turn those 36 bytes into an ASCII image of the characters. And his answer was dead simple:
The structure is clear:
- **36 bytes per glyph** (24 pixels wide x 12 rows, 1 bit per pixel)
- **7,896 total glyphs** — consistent with a full JIS X 0208 Japanese character set
- Glyph 2254 at `0x13CF8` is your match — it looks like a box/frame character (口-like)
- The surrounding glyphs are clearly recognizable as complex kanji
Now the key question is the **mapping** — how glyph index maps to character code. It's likely a Shift-JIS or JIS ordering. Want me to try to figure out the index-to-character mapping? For example, I could look up where known characters (like common kana あ, ア, or specific kanji) should fall in JIS order and see if the glyph at that index matches.
Almost 7000 characters were listed.
I was floored. And what’s more… it worked!
So for a final measure, I ran it against the RADIO.DAT file once again. and Voila… the entire staff commentary, translated. I spot checked a couple (turning the binary into a picture and comparing the kanji), and as far as I can tell it’s got good translations coming for the most part, at least if they’re run thru google translate they’re not nonsensical.
Here are a couple examples.
"この周波数では「メタルギア ソリッド」
制作スタッフによる制作過程での裏話など
をお伝えします。"
On this channel, we will be sharing behind-the-scenes stories from the Metal Gear Solid production staff.
"ここだけの話ですが、本来このステージは企画になかったんですよ。ゲームの基本ルールである”隠れる事”を理解してもらうために、あとから用意したんです。結果的には武器も"
"無い状態で潜入していくという、ゲーム中で最も緊張するステージとなりました。
(助監督 松花賢和)
Just between you and me, this stage wasn't originally planned. It was added later to help players understand the basic rule of the game, which is to hide. As a result, it became the most tense stage in the game, as players infiltrate without even a weapon.
(Assistant Director Matsuka Masakazu)
"デモ、音声に関してはポリスノーツで\
礗立したストリーミングという手法を
使っています。"
"特にポリゴンデモに関しては音声データと
モーションデータ、エフェクトの情報などを
オリジナルのツールでストリーミングデータ
として作成し、再生しています。"
"モーションのストリーミングに関しては、
かなり業界でも先行したと思うのですが…。
(プログラム監督 植原一充)"
"For demos and audio, we use a technique called streaming, which was developed for Policenauts."
"For polygon demos in particular, we use original tools to create streaming data, including audio data, motion data, and effect information, and then play it back."
"When it comes to motion streaming, I think we were well ahead of the industry...
(Program Director Uehara Kazumitsu)"
What does this mean?
Basically, character matching is now 99% done. There are still some typical Kanji characters that need to be reviewed, but there’s only a few and they can be spot checked. After this, all of the staff commentary can be released. Further, I can move forward on translating them and reading all of the unique entries. Never mind, these are done.
So as of now, any dialogue or text stored in the game that is not SHIFT-JIS is decoded.
Further it leads to a couple things I can ensure the scripts are ready to do. And it might mean something fun coming down the pipeline.
So what’s next?
Given these are now fully translated, I want to see if I can properly patch Integral for the staff commentary to be written in English. This might take a few things to occur, but being able to release the mod for both the original playstation, as well as for the Master Collection, might be really interesting, and a good milestone along the way to a full translation of the Japanese version.
Second, this means there’s basically nothing stopping the full text translation and injection in the undub project, which means a playable beta may be around the corner soon! At the very least, it would have all texts in story sequences done. Further work may need to be done for graphics and other things. I don’t feel comfortable with the quality of the opening credits in the Dock stage, but editing them will involve diving into learning and plotting vram management. The graphics will 100% need to be larger in size to go from Kanji of someone’s name to English characters.
I’m hoping I can find a way to automate the staff call translation, but the one issue we’ll hit is that English does not fit as well into the same amount of space. It may need some adjustments, but we’ll figure that out as we get there.
As always, I’ll keep everyone appraised of the updates as we move forward, but this is a major headache done and dealt with.
:)
J-Rush