Im a dad now, so bad jokes are incoming
Hello, everyone!
As thet title says, I’m a dad! Or well, I will be soon. Without sharing too much detail we’re at the hospital until the baby arrives from this point on, so whenever this gets read I’ll actually be one.
For those worried about progress, I do promise I’m not done with this, though updates may continue to be slow. That said, the last couple days I did actually get some good progress in on a couple things. Let me give a quick overview how it’s going.
Character updates
I know I started this project with the rule of chatgpt not writing code for me. However, I’m finding another place where I’ll allow an exception. As I believe I mentioned prior, the Kanji stored in the game that is not part of their standard fonts are stored as 36-byte graphics data after each radio call, or demo/vox subtitle area. The Kanji are compressed down to a 12x12 character that is nigh indiscernable from a blob, especially when very complex.
So, with my good friend Goblin having completed getting the game script into individual cells in excel files, I decided it was time to try a new matching algorythm. And actually the first couple attempts did quite well at figuring out a number of the characters in demo. Cutscenes don’t have too many specific terms, but there were a fair few. Still, the code actually worked out well, and after spot checking 5 out of maybe 20-30 matches (I checked, it was 44!), I integrated them and we seem to be doing good!
The method that worked was essentially this:
- Ingest the entire game script, and trim the quotes from each end.
- For each dialogue line with a missing character, find the closest matching dialogue line.
- Determine the missing character from there.
Later I added a couple additional steps…
- When ingesting the script, I considered having punctuation breaks, as the matching was difficult when the script is maybe 3 sentences long, and the in-game segments are shorter to be fit on a line of the screen. It led to a lot of matching difficulty. I didn’t implement this but it’s probably something we could improve.
- Instead of a simple match, for each character we try to figure out, we get a match for each of the occurrences and see what is the most likely candidate.
- It looks from the code that we’re only reporting sure matches, but as this resulted in accuracy I did not want to increase any fuzziness that could lead to mismatches.
That said, there were a few left that I manually retreived. And when I do that, I usually find a few other non-matching ones, so many of the characters improved. With that, Demo on disk 1 was completely done! Here’s what that setup looks like…
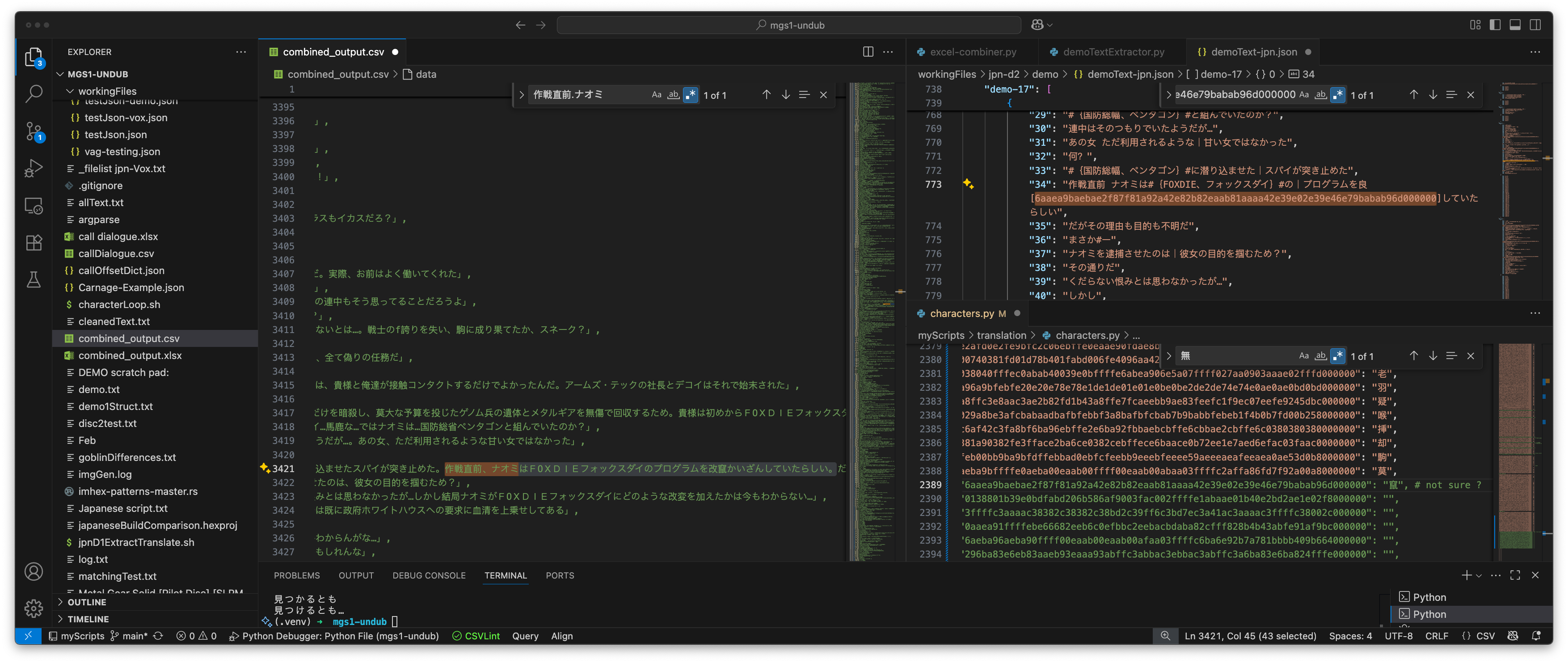
I promise I’m not old and blind, its just easier to be much closer to the Kanji that are drawn so intricately. The flow is:
- Find an occurrence of the binary in the export
- Grab a few characters near there that are unique
- Search for it in the script.
- Visually verify we’re in the same place (If I search something generic like “Snake” スネーク then I’d get a lot, but even a phrase like “Underground maintenance base” could be repeated quite a bit.)
- Add the character based on spacing to the dictionary.
- (Optionally,) I can use another tool to turn the binary into a large graphic to see if it looks like it.
For example…


The first one above turns out to be 竄. Here’s the context I was given:
作戦直前、ナオミはFОXDIEフォックスダイのプログラムを改竄かいざんしていたらしい。
And here’s how it looks in the extraction:
作戦直前 ナオミは#{FOXDIE、フォックスダイ}#の|プログラムを良[6aaea9baebae2f87f81a92a42e82b82eaab81aaaa42e39e02e39e46e79babab96d000000]していたらしい",
See why this is a PITA?
And finally… 7. After 4-5 characters, I usually re-ran extraction to fix the characters.
Along the way there were some I’d spot that were not correct, and I’d search for them in the characters, comment it out, and verify what code it was. That way some previous mismatches could be corrected.
I had GPT a couple quick mods to the script for extracting the demo text, as I previously had an override to skip any demos with no text, but it was hard coded to run even though discs 1 and 2 had different cutscenes (unlike Radio where they are near identical). But after that, extracting disk 2 and running the same script it found a whopping… 12? new characters. I’m okay with it not getting a ton as long as they are sure matches. So in an hour or two I banged out the rest of the unknown characters and voila… all cutscene characters are identified!
Honorable mention: ChatGPT outperforms local AI by a large margin.
https://chatgpt.com/s/t_6886676e58e48191af488d97ba8cc770
It’s worth mentioning that when I’m super stuck because something doesn’t look right, its nice that models are trained in multiple languages. This was one time where ChatGPT was far better at figuring out which caracter was missing.
Unfortunately, none of the local models I tried were able to deduce the same correct character. I want to do more testing, but in the meantime, I guess it is what it is.
Current status
Okay so I forgot where I was for a bit. So I’ve moved onto radio/codec. The same algorythm only found… 6 characters. But the good news is only 111 remain unidentified. So the next steps will be continuing to get some manual checks in. Hopefully this can still move moderatly well.
Past that, what isn’t yet identified is going to be technical Kanji found in integral for the Staff commmentary. I do plan to use tools to translate those into english for the Integral version, but it’s not primary to my project, so it’ll be something I hit down the line.
What are next?
I’m gonna take a stab at some of those 111 characters. Maybe I can get a few hammered out and then I never have to think about them again.
Past that, I may pivot back to the GUI, only becuase I can manually add extra lines in DEMO but it’s not as easy with radio because the subtitles come from RADIO.DAT. Timings I will need to test editing in VOX, but it’s unclear if i can make multiple subtitles appear.
A tool to make demo easier (rather than a lot of manual renumbering) would be great, but we’ll see if I get there or not.
I do also want to try improving the character recognition a bit. Maybe it’ll cut down on the 111. I feel a little raw still about only using AI to find the right algorythms to match characters, but the character matching manually might be too much of a time sync.
Lastly it would also be good to develop a QC for the matching via AI, but i’ll have to think heavily on how to do that.
–
Updates may slow even further, but I’m still working on it. Probably for the rest of my time here I’ll set up something to get the distribution list sending via email, as I’ve yet to get that done.
Until next time!